为什么 JavaScript 会栈溢出
先回答问题:造成栈溢出的原因就是调用栈中的执行上下文堆叠过多没有返回。
哪些情况下代码才算是“一段”代码,才会在执行之前就进行编译并创建执行上下文。
- 当 JavaScript 执行全局代码的时候会编译全局代码并创建全局执行上下文,整个页面生命周期里,全局执行上下文只有一个。
- 当调用一个函数的时候,函数内部的代码会被编译,并创建函数执行上下文,一般情况下,函数执行结束后,创建的函数执行上下文会被销毁。
- 当使用 eval 函数的时候,eval 的代码也会被编译,并创建执行上下文。
什么是调用栈?
调用栈就是用来管理函数调用关系的一种数据结构。那什么是函数调用,什么是栈结构。
什么是函数调用?
就是给你声明的函数名后面跟一对小括号。看以下代码
var a = 1;
function add() {
var b = 2;
return a + b;
}
add();创建了一个 add 函数,然后随后调用了 add 函数
分析一下流程
首先 JavaScript 执行全局代码的时候会编译全局代码并创建全局执行上下文(过程中变量提升了 a=undefined,然后将函数也提升了,并存放在全局执行上下文中的变量环境中)
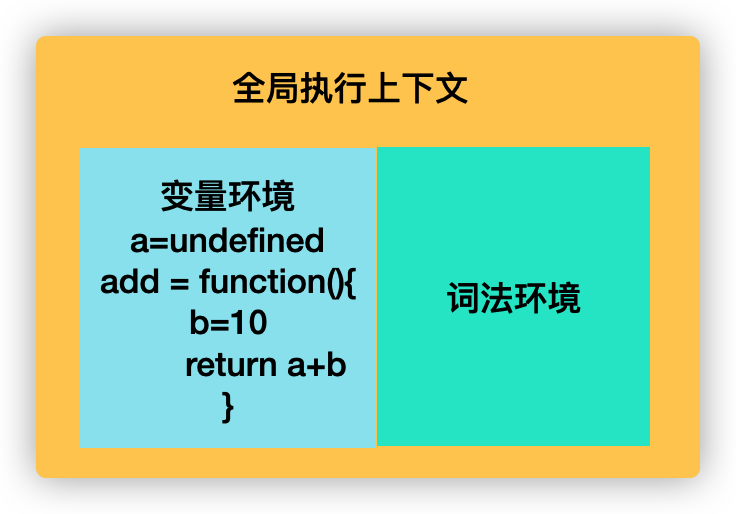
然后开始执行可执行代码(就两句a=1和add()),执行到 add()的时候,JavaScript 判断这是一个函数调用,所以执行以下操作
- 首先从全局执行上下文中的变量环境中拿出 add 函数代码。
- 然后对 add 函数的这段代码进行编译,创建该函数的执行上下文和可执行代码。

- 然后执行可执行代码,输出结果。
我们发现此时已经有两个执行上下文了,一个是全局执行上下文,一个是 add 函数的执行上下文。在 JavaScript 的执行过程中,会存在多个执行上下文,那这些执行上下文 JavaScript 引擎是如何管理的呢?
是通过一个叫栈的数据结构来管理的。
什么是栈
一种数据结构,栈中元素满足后进先出

类比一下就像下面这么一串铜钱,你只能从一端加钱或者取钱

什么是 JavaScript 的调用栈,JavaScript 就是用栈这种结构来管理执行上下文的,当执行上下文创建好以后,JavaScript 引擎会将执行上下文压入栈中,通常把这种管理执行上下文的栈叫执行上下文栈也叫调用栈。
来看一段稍微复杂点的代码
var a = 2;
function add(b, c) {
return b + c;
}
function addAll(b, c) {
var d = 10;
result = add(b, c);
return a + result + d;
}
addAll(3, 6);第一步,创建全局上下文,并将其压入栈底。

可以看到全局上下文的变量环境包括变量 a 和函数 add 以及函数 addAll。然后开始执行全局可执行代码a=2和addAll(3,6)。
首先执行a=2的赋值操作,执行该语句会将全局上下文环境中 a 的值设置为 2。
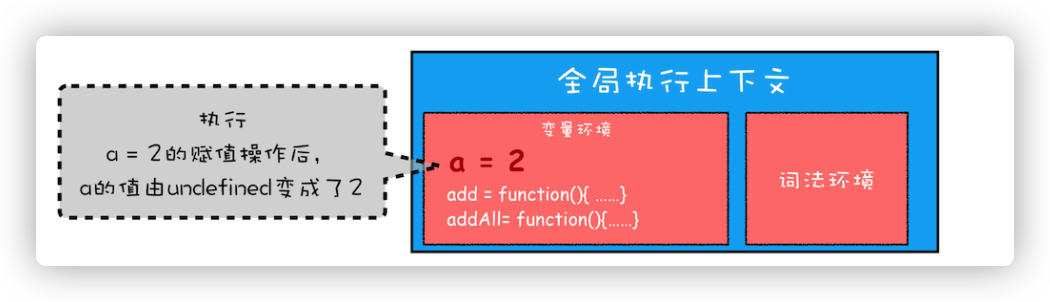
接下来调用 addAll 函数。当调用该函数的时候,JavaScript 引擎会编译该函数,并为其创建一个执行上下文,最后还将该函数的执行上下文压入栈中。
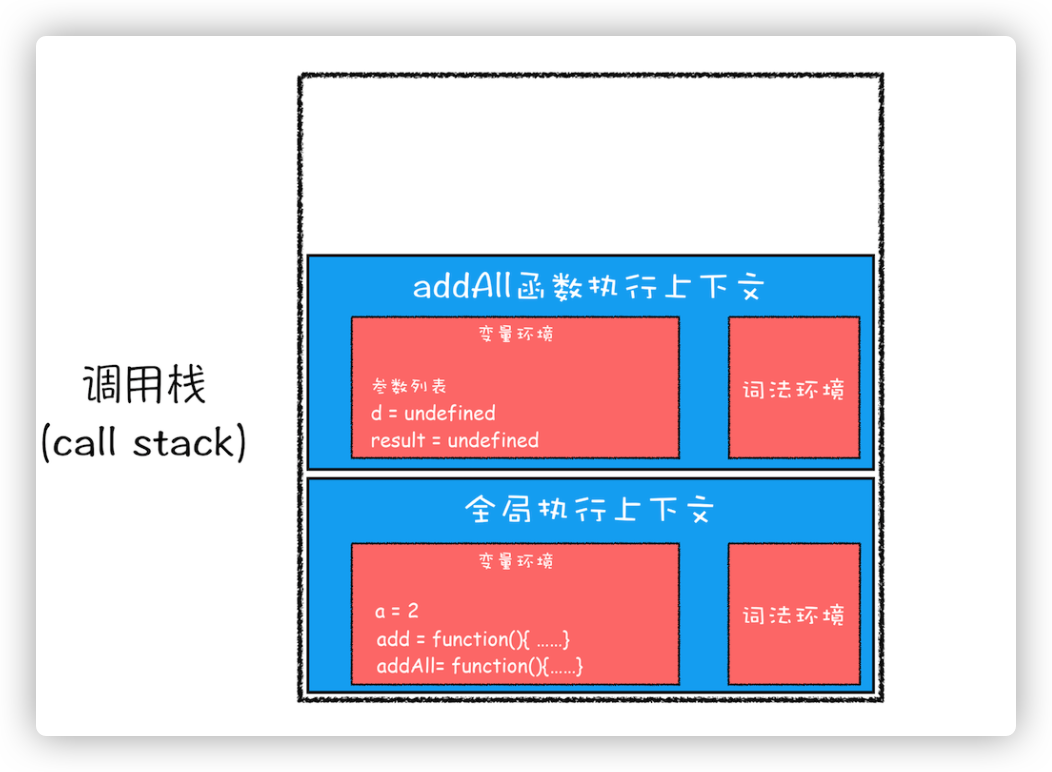
addAll 函数的执行上下文创建好之后,就进入函数代码执行阶段了,这里执行了 d=10 的赋值操作,此时会让 addAll 的变量环境中的 d=undefined 变成 d=10,然后执行到 result=add(b,c)的时候,也就是执行到 add 函数的调用语句,从而为 add 函数创建执行上下文,并压入了调用栈。如下图
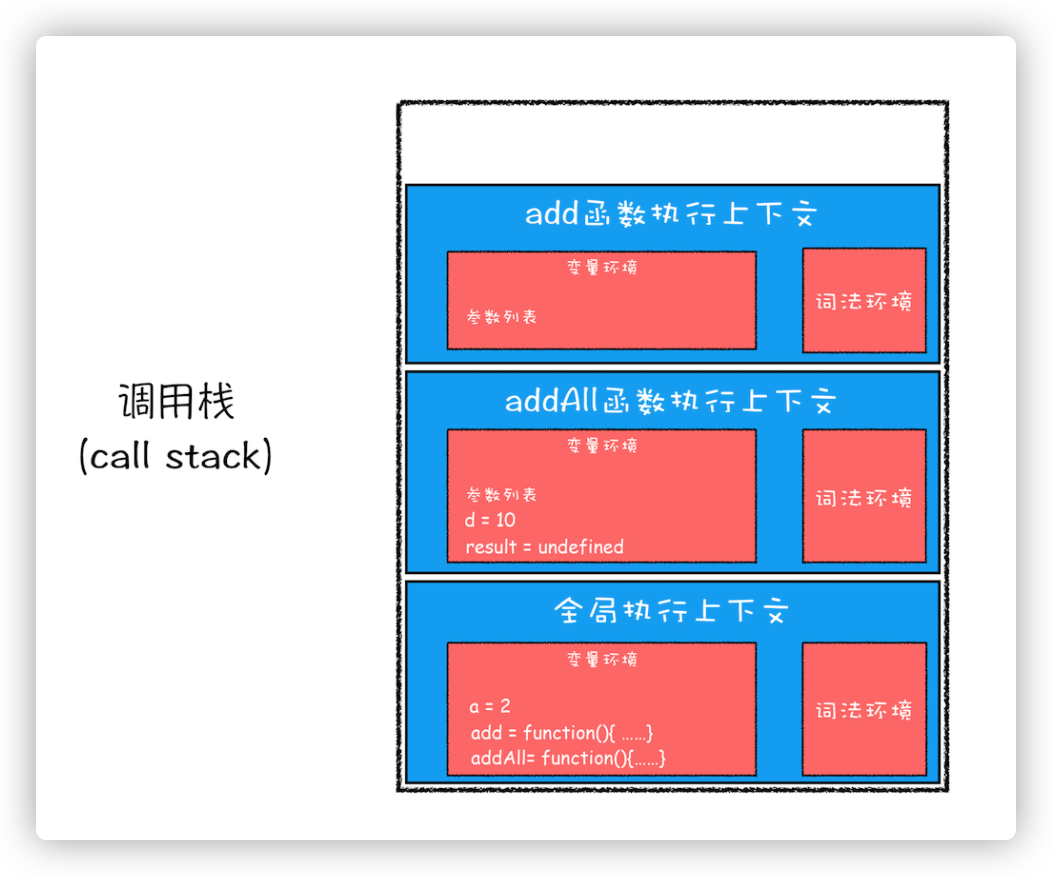
当 add 函数返回的时候,该函数的执行上下文就会从栈顶弹出,并将 addAll 函数执行上下文中变量环境的 result 的值设置为 add 函数的返回值,也就是 9。
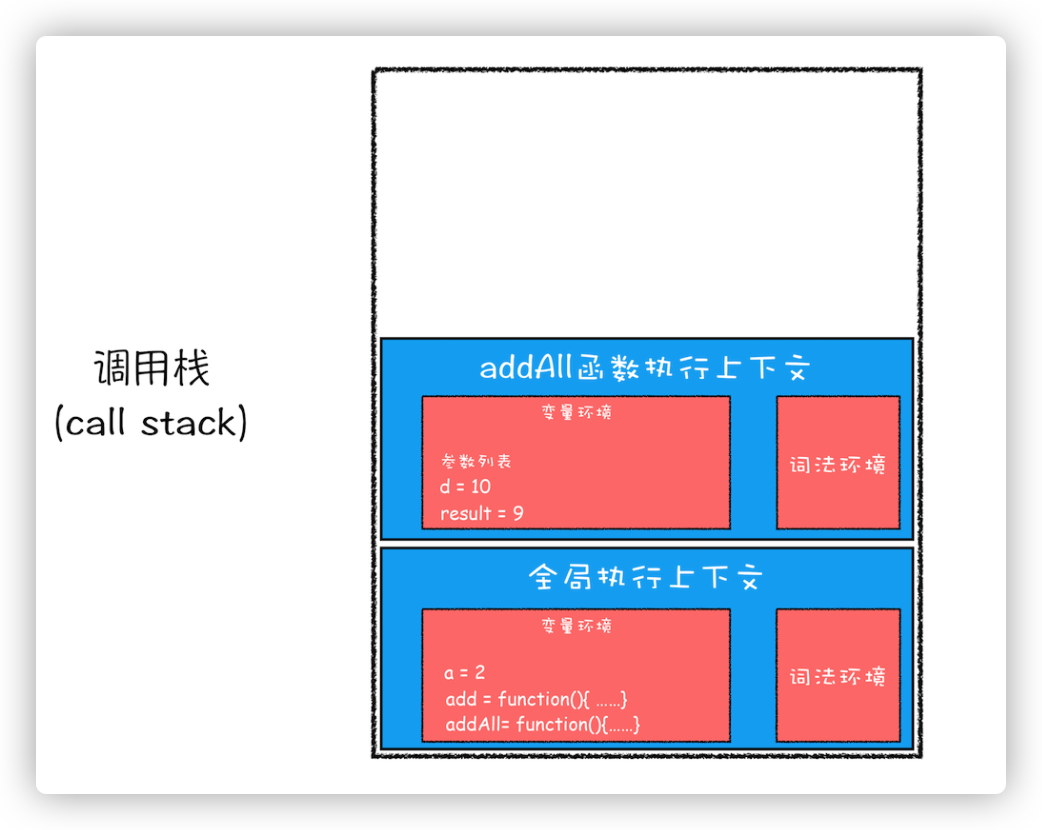
然后 addAll 执行相加操作并返回,addAll 的执行上下文也会从栈顶部弹出,此时调用栈就只剩全局上下文了。
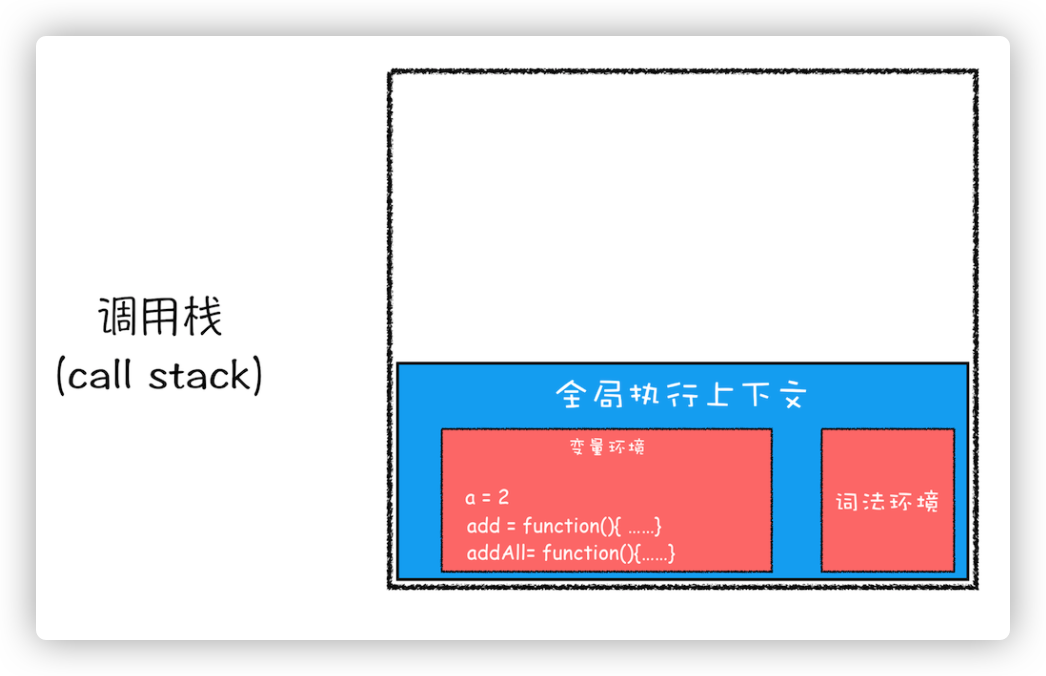
此时流程结束了。
结论:调用栈是 JavaScript 引擎追踪函数执行的一个机制,当一次有多个函数被调用时,通过调用栈就能够追踪到哪个函数正在被执行以及各函数之间的调用关系。
开发中如何查看调用栈
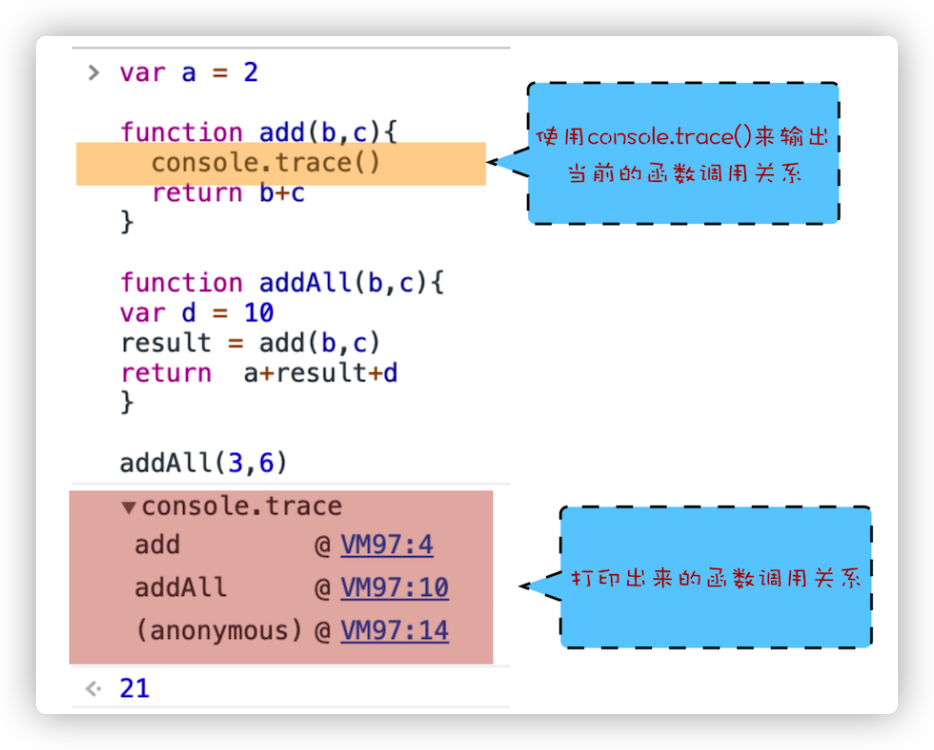
可以输入一段代码,然后在你需要知道调用关系的函数声明里塞一句console.trace()
什么是栈溢出
调用栈是有大小的,当入栈的执行上下文超过一定数目,JavaScript 引擎就会报错,这种错误就叫做栈溢出。
比如写一个一直没有边界一直自己调用自己的递归函数
function cl() {
console.log(cl());
}
console.log(cl());导致报错,可以看报错信息,意思就是超过了最大栈调用大小。

之前那个案例每个函数去调用另一个函数的时候执行可执行代码最后都会返回,那如果没返回一直在自调用是什么概念,那就是一直不停的往调用栈里塞新创建的函数执行上下文,但是栈是有容量限制的,因此最后就会导致栈溢出的错误。
可以用一些方法来避免栈溢出问题,比如把递归调用改成别的形式,或是用定时器的方法来将当前的任务拆分成其他很多小任务。
因为 setTimeout 是浏览器的 API,每次运行 setTimeout 的时候会先调用浏览器的 API,当倒计时到的时候回调函数就会加到任务队列中,然后当调用栈,例如
function runStack(n) {
if (n === 0) return 100;
return setTimeout(function () {
runStack(n - 2);
}, 0);
}
runStack(50000);Contributors
 Annan
Annan